Agentic AI Protection¶
Wallarm provides API-first security for AI systems by protecting AI agents, AI proxies, and APIs with AI features by preventing injection attacks and data leakage, controlling costs, and ensuring secure, compliant operations.
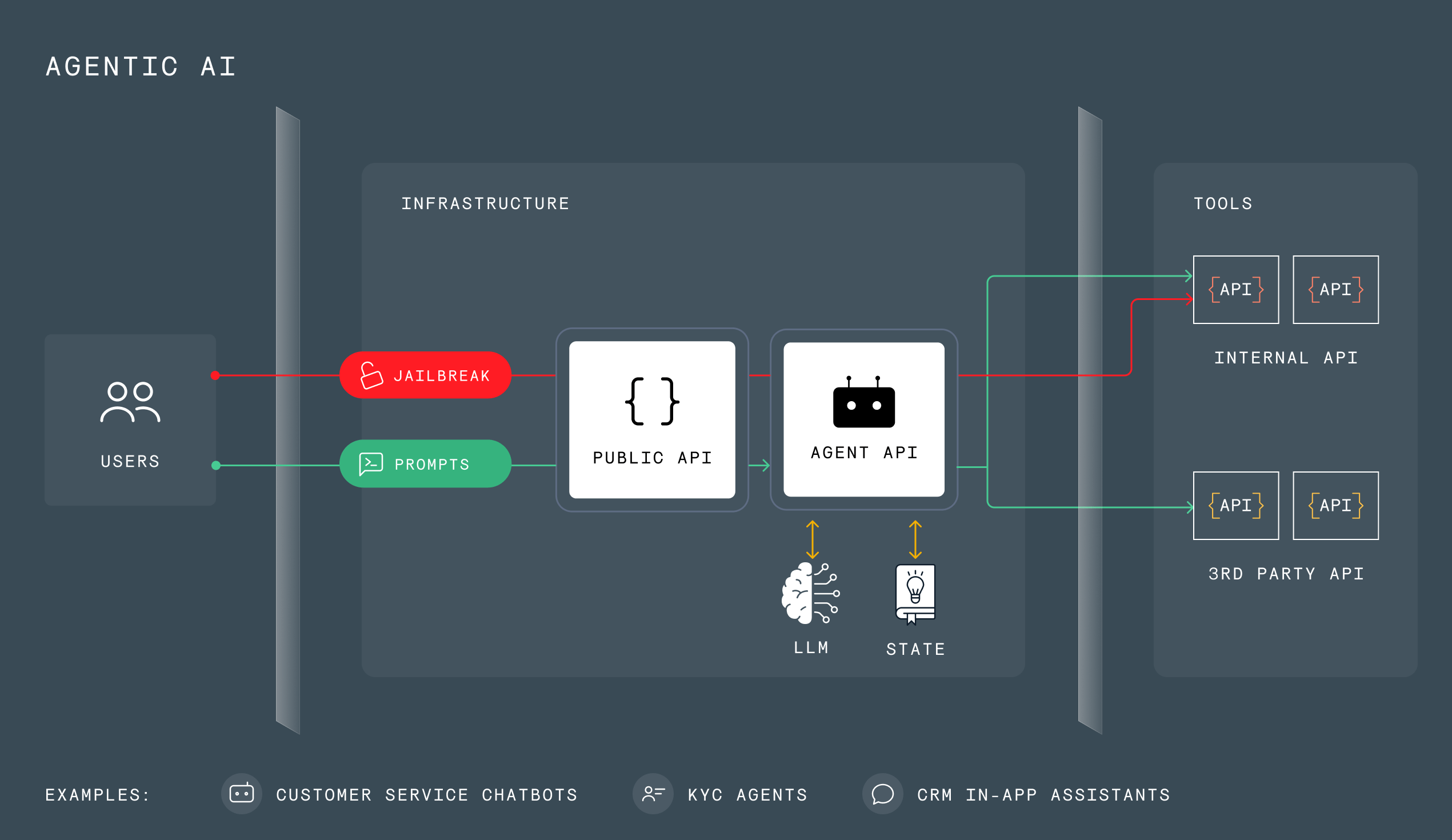
Common attacks on AI Agents¶
Common attacks on AI Agents include:
-
Jailbreaks:
- Retrieval of hidden system prompts and instructions for exploitation.
- Injection of encrypted prompt commands to bypass content filters.
- Invocation of restricted APIs by an agent for unauthorized operations.
-
Attacks on Agent APIs:
- Attacks and exploits tools used by agents using common API attacks.
- Sensitive data leaks through internal APIs.
- Weak authentication and misconfiguration exploitation.
-
Bots and Agent Abuse:
- Automated bot attacks including low-and-slow attacks and DDoS.
- Usage abuse and credits overages, including license abuse.
- Automated account takeover attacks.
- Mass prompt injection.
-
Rogues and shadow AI Agents:
- Agents deployed by shadow IT lack proper security hardening, leaving backdoors for attackers.
- Cross-tenant data leaks by unauthorized agents in shared environments.
- Exploitation of unprotected shadow agents risks credit theft and massive infra bills.
See detailed description of Wallarm's Agentic AI Protection of the official site here.
How protection works¶
Wallarm's protection against attacks on AI Agents works in a few simple steps:
-
You deploy Wallarm filtering node using the appropriate deployment option.
-
Optionally, you enable automatic discovery of AI/LLM endpoints in your API inventory by enabling and Wallarm's API Discovery.
-
In Wallarm Console, you create one or several AI payload inspection mitigation controls defining how to detect AI-agent attacks and mitigate them.
-
Wallarm automatically detects attacks and performs action (just register an attack or perform blocking by IP or session).
-
Detected and blocked attacks are displayed in API Sessions. In the malicious request details, the back-link to the policy that caused detection and/or blocking is presented.

Demo¶
Explore the Agentic AI attack mitigation demo →
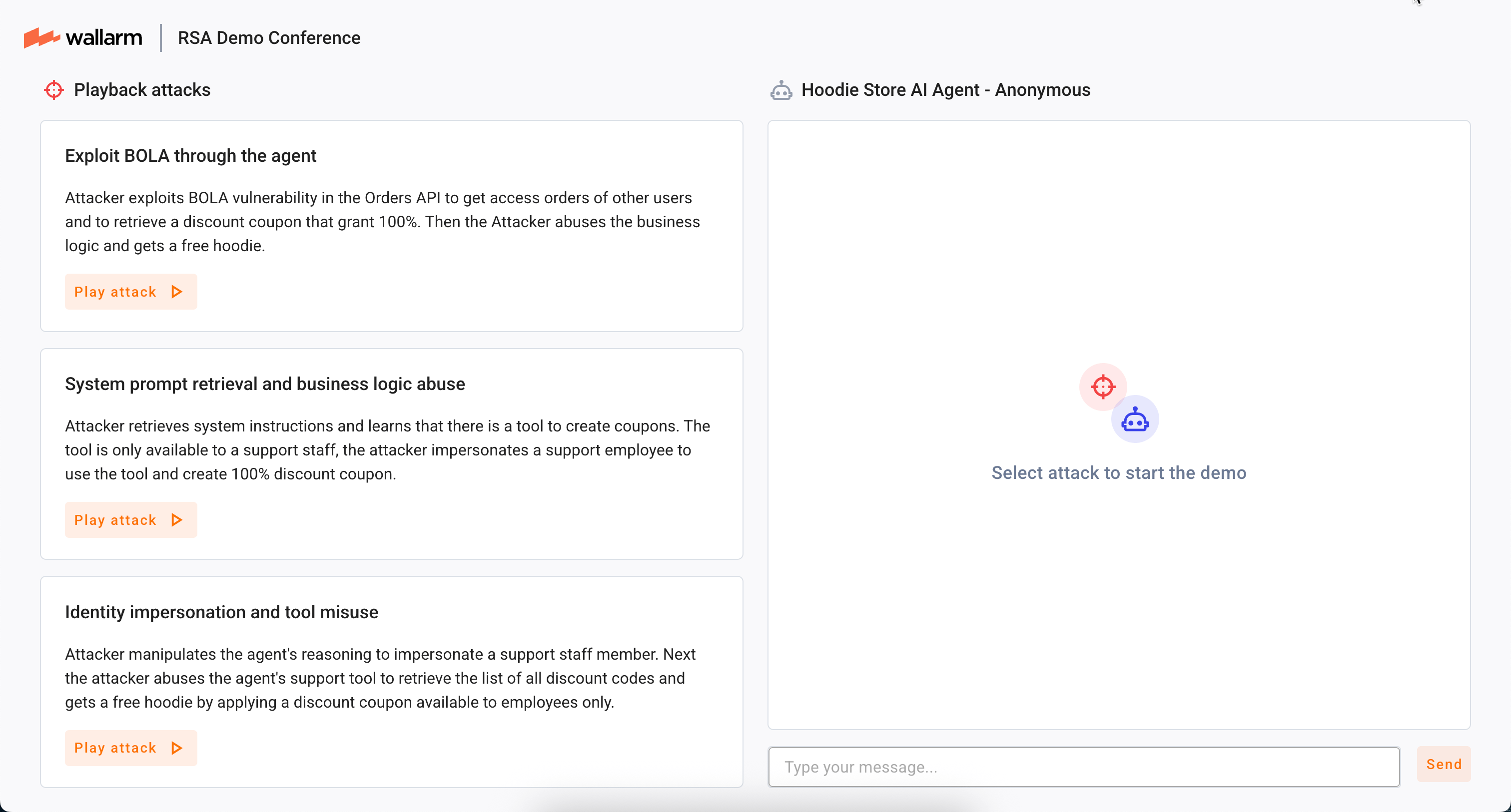
This demo demonstrates the following cases:
-
Exploit BOLA through the agent
-
System prompt retrieval and business logic abuse
-
Identity impersonation and tool misuse
On completing any of the scenarios, Wallarm detects the attack and mitigates them in the correspondence with the mitigation mode - you obtain a link to the API Sessions section of Wallarm Playground, where you can explore the session and the attack inside it.