Sensitive Data Detection  ¶
¶
API Discovery detects and highlights sensitive data consumed and carried by your APIs and MCP primitives, which allows applying encryption, tokenization, or other security controls to protect it and prevent data breaches and the transmission of sensitive data across insecure channels or to unauthorized systems.
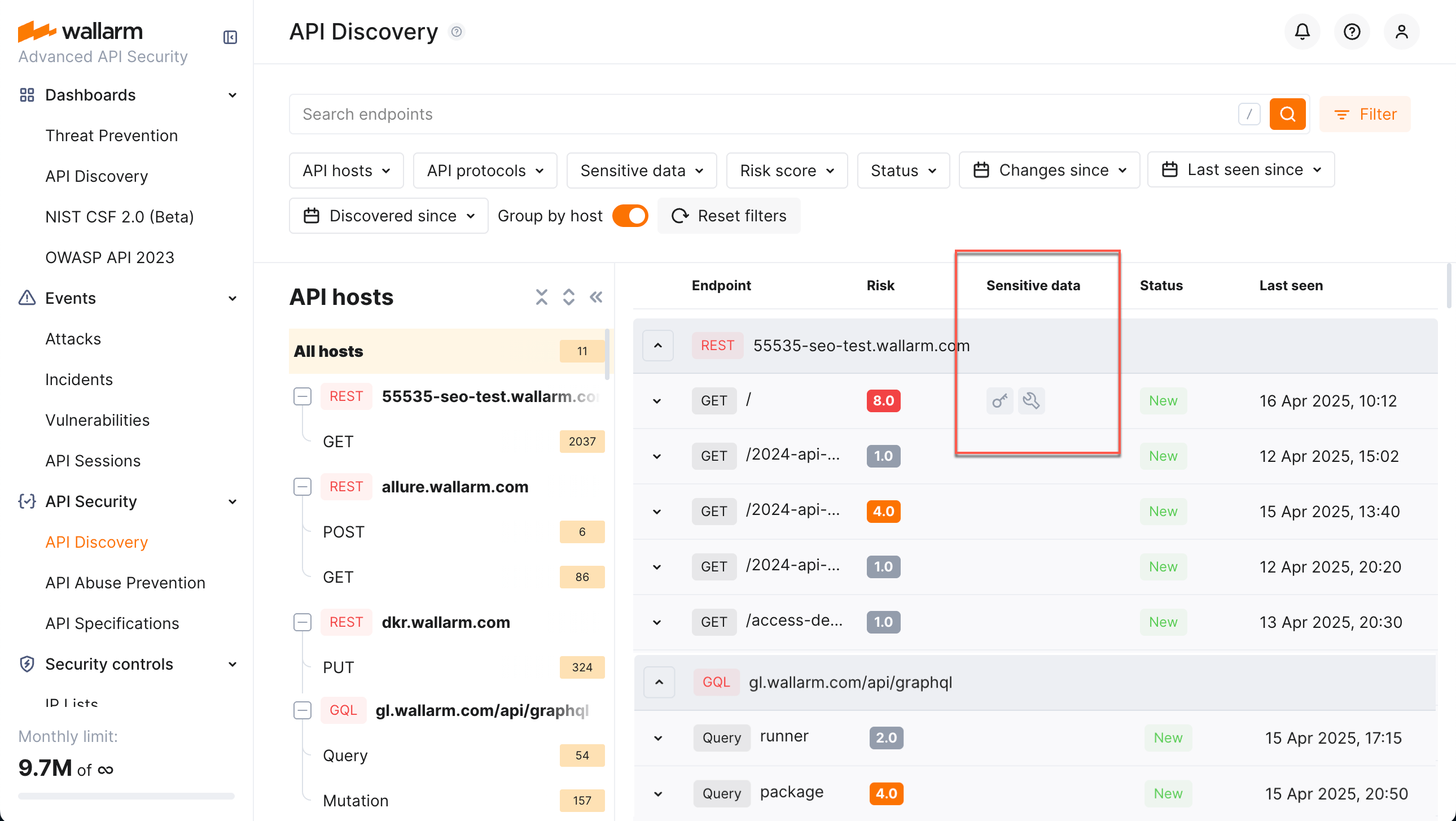
API Discovery detects the following types of sensitive data:
-
Personally identifiable information (PII) like full name, passport number or SSN
-
Login credentials like secret keys and passwords
-
Financial data like bank card numbers
-
Medical data like medical license number
-
Technical data like IP and MAC addresses
In Wallarm Console, go to API Discovery → Configure → Sensitive data to check the list of default sensitive data patterns provided for each of listed types.
Customizing sensitive data detection¶
To make sensitive data detection fully comply with your company's specific needs and industry-specific regulations such as GDPR, HIPAA, PCI DSS, etc., API Discovery provides the ability to fine-tune the detection process.
Customization empowers you to meet your company's unique data protection obligations. Additionally, if any proprietary or specialized sensitive data elements are presented in your data flows, you will benefit from the ability to define custom regular expressions for their precise identification.
Sensitive data detection is configured with the set sensitive data patterns - each pattern defines specific sensitive data and settings for its search. API Discovery goes with the set of default patterns. You can modify default patterns and add your own in Wallarm Console → API Discovery → Configure API Discovery → Sensitive data.
You can modify or disable the default (out-of-box) patterns and quickly restore them to initial settings if necessary. Your own patterns can be created, modified, disabled and deleted at any moment.
Confidence scores
You can use patterns and context words to configure your sensitive data detection. Choose the confidence scores from 0.1 to 1.0 for your patterns and context words to specify how confident you are that matching this expression or the presence of the string or word next to the sensitive data means the presence of sensitive data. Use appropriate scores to detect more real entities and produce fewer false positives.
The sensitive data is detected if score threshold of 0.3 is reached or exceeded: the context word scores are summed up, from the patterns the biggest is taken. See examples below for better understanding.
You should adjust confidence scores after trying them on actual traffic data.
Pattern-based detection
Use a regular expression in PCRE format to match the expected sensitive data value. When you use a regular expression, detection becomes much more precise. You can use several patterns with different scores. If any is matched, the sensitive data is detected.
Patterns are suitable for fixed-length tokens, IDs, and URIs.
Context words
Wallarm looks at the words around the suspected sensitive data that match the pattern. If any of the context words is found, it boosts the resulting confidence score. The context can come from URL path, query parameter name, JSON keys, and other parameters next to it.
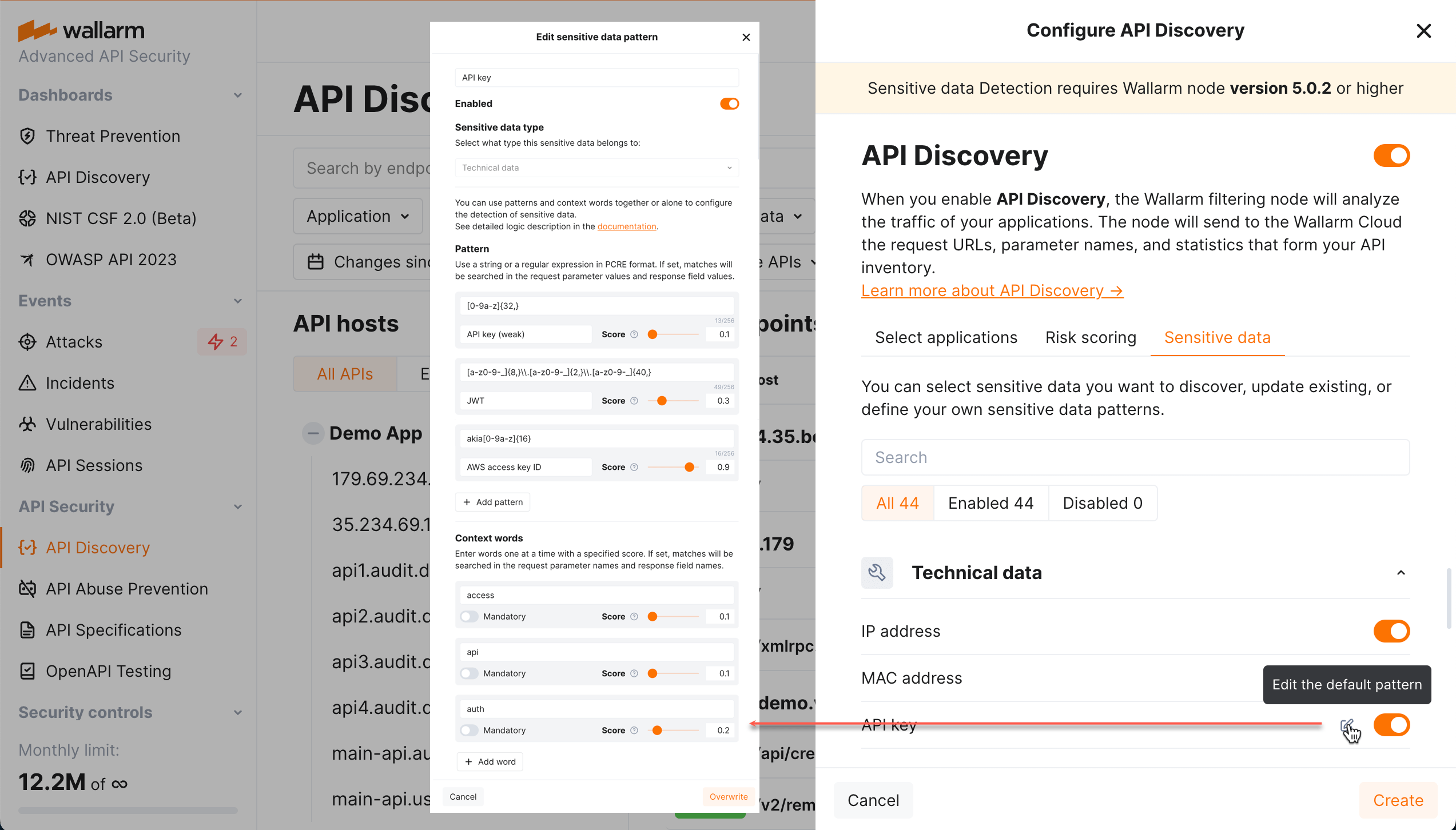
For example, on the picture above, the sensitive data will be detected:
-
Immediately if the match to
JWTorAWS access key IDpattern is found. -
If the match to
AWS key (weak)is found, by itself it will not result in "yes" (score of0.1is below threshold of0.3). -
But with the context words
access(0.1) andapi(0.1) the sum becomes0.3and sensitive data is detected. -
If we mark
authas mandatory, the situation changes: in absence ofauth, scores of presentedaccessandapiwill be ignored and cannot boost the pattern's score.
Context word only-based detection
If you specify context words without patterns, Wallarm decides on sensitive data presence based on the presence of the words. The higher the sum of the confidence scores, the more likely the parameter will be marked as having your described sensitive data.
For some context-only searches, it is necessary to declare some words as mandatory: if the mandatory word is not present in the value's context, the parameter does not contain sensitive data.
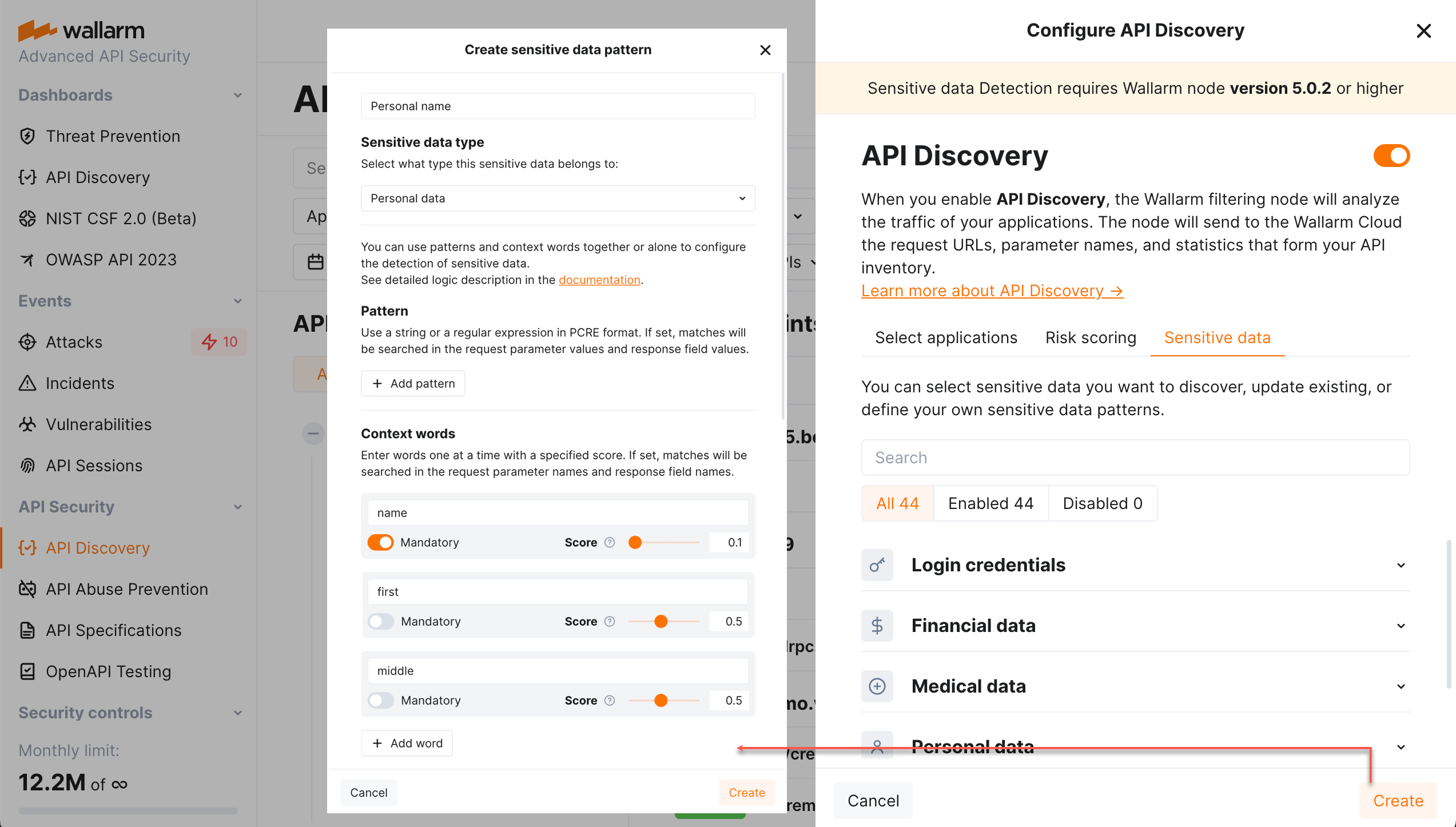
Example: personal_name
Context words:
-
name
-
first
-
middle
We must match middle_name, but not name or middle. So, we set a score for name to 0.1 so we will not match name. But we must give middle a big score of 0.5 because "middle_name" is a strong combination.
To prevent us from detecting "middle" without name, we mark name as mandatory for an entity. If name is not found, no sensitive data is detected.
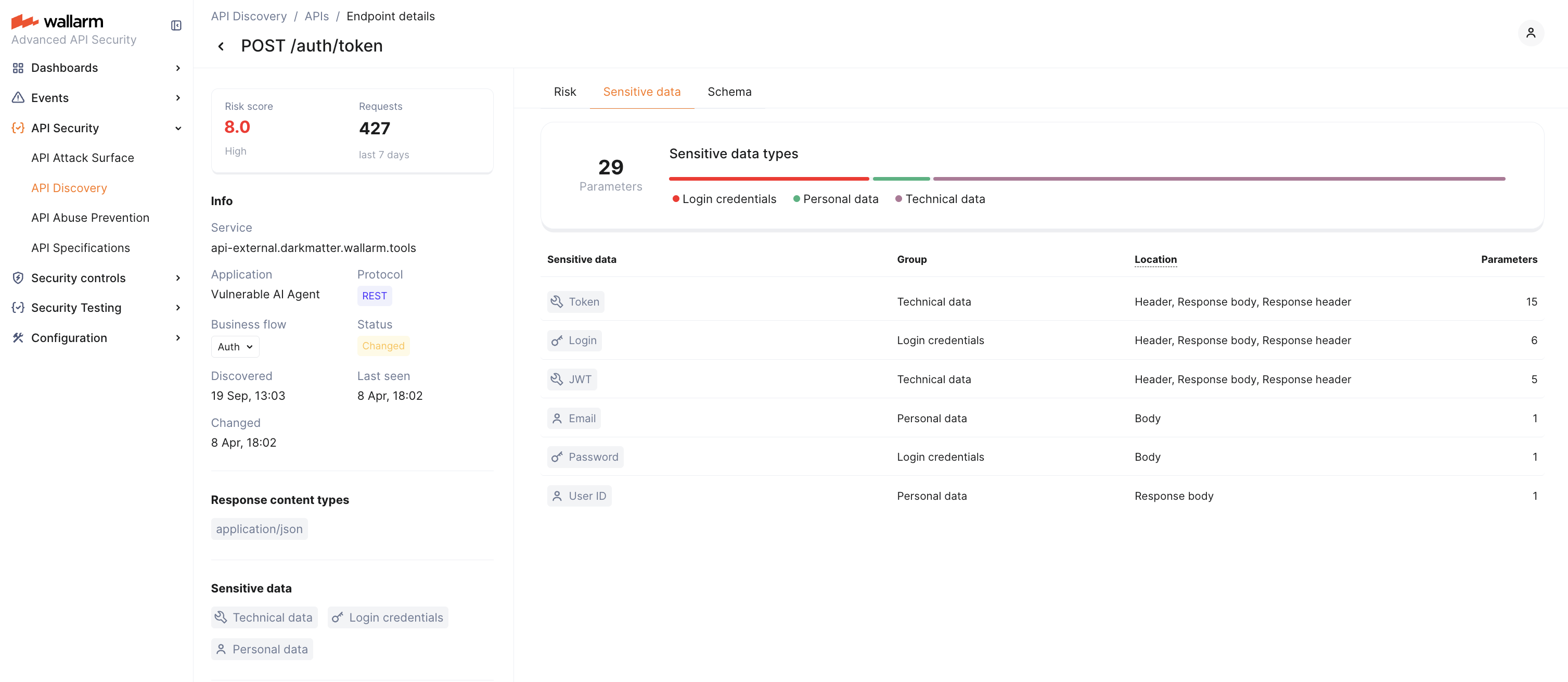
Viewing sensitive data in endpoint details¶
On the endpoint's details page, the Sensitive data tab shows which parameters carry sensitive data, the exact sensitive data type detected for each parameter, and the request or response location (headers, body, query) where it was found.